MindVoice Research Project, ESC Group
Technology
Python, TensorFlow, Git, GitHub, Weights & Biases
Timeline
May 2023 – Present
Role
Research Assistant
Location
ESC Group, University at Buffalo, Buffalo, New York, USA


Our Paper got Accepted to IEEE/ACM Chase’ 24! Anarghya Das, Puru Soni, Ming-Chun Huang, Wenyao Xu, “Multimodal Speech Recognition using EEG and Audio Signals: A Novel Approach for Enhancing ASR Systems”, IEEE International Conference on Connected Health: Applications, Systems and Engineering Technologies [CHASE’24], Wilmington, Delaware, USA, June 2024
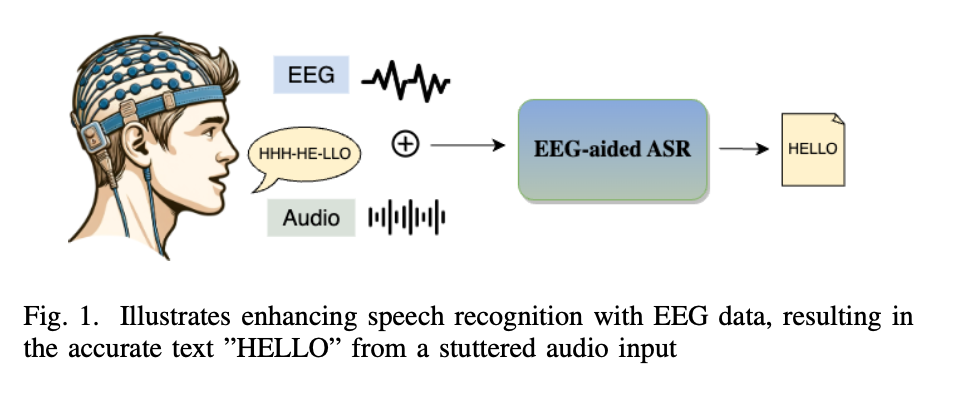
I’m currently collaborating on the MindVoice research project, mentored by Wenyao Xu, to improve Automatic Speech Recognition (ASR) for people with speech impairments by adopting a combination of Audio and Brainwave (EEG) data.
We used Python to extract MFCCs from Noisy Audio with the Librosa library, and Frequency Domain Cross Covariance Matrices from EEG with NumPy.
I took a Multimodal approach and utilized TensorFlow to implement a GRU encoder for Audio MFCCs and a Convolutional Neural Network encoder for EEG Frequency Domain Cross Covariance Matrices (see figure).
We wrote a paper detailing our efforts and results, including the effects of noisy audio on the multimodal model. Multimodal model was found to be more robust to noise compared to the Audio-only model.
